

虽然python或r编程语言有一个相对容易的学习曲线,但是Web开发人员更喜欢在他们舒适的javascript区域内做事情。目前来看,node.js已经开始向每个领域应用javascript,在这一大趋势下我们需要理解并使用JS进行机器学习。由于可用的软件包数量众多,python变得流行起来,但是JS社区也紧随其后。这篇文章会帮助初学者学习如何构建一个简单的分类器。
扩展:
很棒的机器学习库,可以在你的下一个应用程序中添加一些人工智能! Big.bitsrc.io创建
我们可以创建一个使用tensorflow.js在浏览器中训练模型的网页。考虑到房屋的“avgareanumberofrows”,模型可以学习去预测房屋的“价格”。
为此我们要做的是:
加载数据并为培训做好准备。
定义模型的体系结构。
训练模型并在训练时监控其性能。
通过做出一些预测来评估经过训练的模型。
第一步:让我们从基础开始
创建一个HTML页面并包含JavaScript。将以下代码复制到名为index.html的HTML文件中。
TensorFlow.js Tutorial
为代码创建javascript文件
在与上面的HTML文件相同的文件夹中,创建一个名为script.js的文件,并将以下代码放入其中。
console.log('Hello TensorFlow'); 测试
既然已经创建了HTML和JavaScript文件,那么就测试一下它们。在浏览器中打开index.html文件并打开devtools控制台。
如果一切正常,那么应该在devtools控制台中创建并可用两个全局变量:
- tf是对tensorflow.js库的引用
- tfvis是对tfjs vis库的引用
现在你应该可以看到一条消息,上面写着“Hello TensorFlow”。如果是这样,你就可以继续下一步了。

需要这样的输出
注意:可以使用Bit来共享可重用的JS代码
Bit(GitHub上的)是跨项目和应用程序共享可重用JavaScript代码的最快和最可扩展的方式。可以试一试,它是免费的:
Bit是开发人员共享组件和协作,共同构建令人惊叹的软件的地方。发现共享的组件…
Bit.dev例如:Ramda用作共享组件
一个用于JavaScript程序员的实用函数库。-256个javascript组件。例如:等号,乘…
Bit.dev第2步:加载数据,格式化数据并可视化输入数据
我们将加载“house”数据集,可以在找到。它包含了特定房子的许多不同特征。对于本教程,我们只需要有关房间平均面积和每套房子价格的数据。
将以下代码添加到script.js文件中。
async function getData() { Const houseDataReq=awaitfetch('https://raw.githubusercontent.com/meetnandu05/ml1/master/house.json'); const houseData = await houseDataReq.json(); const cleaned = houseData.map(house => ({ price: house.Price, rooms: house.AvgAreaNumberofRooms, })) .filter(house => (house.price != null && house.rooms != null)); return cleaned;} 这可以删除没有定义价格或房间数量的任何条目。我们可以将这些数据绘制成散点图,看看它是什么样子的。
将以下代码添加到script.js文件的底部。
async function run() { // Load and plot the original input data that we are going to train on. const data = await getData(); const values = data.map(d => ({ x: d.rooms, y: d.price, })); tfvis.render.scatterplot( {name: 'No.of rooms v Price'}, {values}, { xLabel: 'No. of rooms', yLabel: 'Price', height: 300 } ); // More code will be added below}document.addEventListener('DOMContentLoaded', run); 刷新页面时,你可以在页面左侧看到一个面板,上面有数据的散点图,如下图。
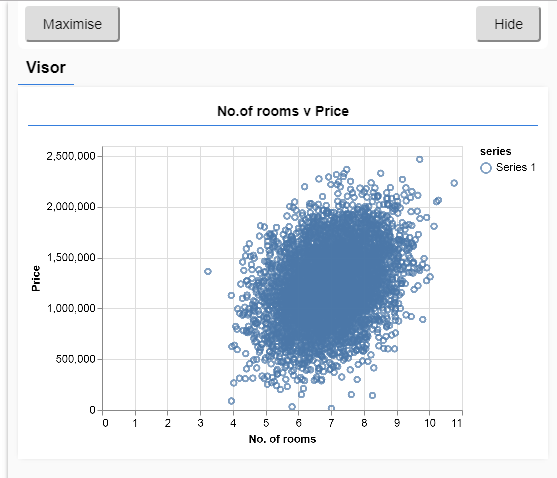
散点图
通常,在处理数据时,最好找到方法来查看数据,并在必要时对其进行清理。可视化数据可以让我们了解模型是否可以学习数据的任何结构。
从上面的图中可以看出,房间数量与价格之间存在正相关关系,即随着房间数量的增加,房屋价格普遍上涨。
第三步:建立待培训的模型
这一步我们将编写代码来构建机器学习模型。模型主要基于此代码进行架构,所以这是一个比较重要的步骤。机器学习模型接受输入,然后产生输出。对于tensorflow.js,我们必须构建。
将以下函数添加到script.js文件中以定义模型。
function createModel() { // Create a sequential model const model = tf.sequential(); // Add a single hidden layer model.add(tf.layers.dense({inputShape: [1], units: 1, useBias: true})); // Add an output layer model.add(tf.layers.dense({units: 1, useBias: true})); return model;} 这是我们可以在tensorflow.js中定义的最简单的模型之一,我们来试下简单分解每一行。
实例化模型
const model = tf.sequential();
这将实例化一个tf.model对象。这个模型是连续的,因为它的输入直接流向它的输出。其他类型的模型可以有分支,甚至可以有多个输入和输出,但在许多情况下,你的模型是连续的。
添加层
model.add(tf.layers.dense({inputShape: [1], units: 1, useBias: true})); 这为我们的网络添加了一个隐藏层。因为这是网络的第一层,所以我们需要定义我们的输入形状。输入形状是[1],因为我们有1这个数字作为输入(给定房间的房间数)。
单位(链接)设置权重矩阵在层中的大小。在这里将其设置为1,我们可以说每个数据输入特性都有一个权重。
model.add(tf.layers.dense({units: 1})); 上面的代码创建了我们的输出层。我们将单位设置为1,因为我们要输出1这个数字。
创建实例
将以下代码添加到前面定义的运行函数中。
// Create the modelconst model = createModel(); tfvis.show.modelSummary({name: 'Model Summary'}, model); 这样可以创建实例模型,并且在网页上有显示层的摘要。
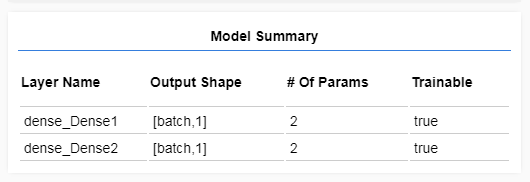
步骤4:为创建准备数据
为了获得TensorFlow.js的性能优势,使培训机器学习模型实用化,我们需要将数据转换为Tensors。
将以下代码添加到script.js文件中。
function convertToTensor(data) { return tf.tidy(() => { // Step 1. Shuffle the data tf.util.shuffle(data); // Step 2. Convert data to Tensor const inputs = data.map(d => d.rooms) const labels = data.map(d => d.price); const inputTensor = tf.tensor2d(inputs, [inputs.length, 1]); const labelTensor = tf.tensor2d(labels, [labels.length, 1]); //Step 3. Normalize the data to the range 0 - 1 using min-max scaling const inputMax = inputTensor.max(); const inputMin = inputTensor.min(); const labelMax = labelTensor.max(); const labelMin = labelTensor.min(); const normalizedInputs = inputTensor.sub(inputMin).div(inputMax.sub(inputMin)); const normalizedLabels = labelTensor.sub(labelMin).div(labelMax.sub(labelMin)); return { inputs: normalizedInputs, labels: normalizedLabels, // Return the min/max bounds so we can use them later. inputMax, inputMin, labelMax, labelMin, } }); } 接下来,我们可以分析一下将会出现什么情况。
随机播放数据
// Step 1. Shuffle the data tf.util.shuffle(data);
在训练模型的过程中,数据集被分成更小的集合,每个集合称为一个批。然后将这些批次送入模型运行。整理数据很重要,因为模型不应该一次又一次地得到相同的数据。如果模型一次又一次地得到相同的数据,那么模型将无法归纳数据,并为运行期间收到的输入提供指定的输出。洗牌将有助于在每个批次中拥有各种数据。
转换为Tensor
// Step 2. Convert data to Tensorconst inputs = data.map(d => d.rooms)const labels = data.map(d => d.price);const inputTensor = tf.tensor2d(inputs, [inputs.length, 1]);const labelTensor = tf.tensor2d(labels, [labels.length, 1]);
这里我们制作了两个数组,一个用于输入示例(房间条目数),另一个用于实际输出值(在机器学习中称为标签,在我们的例子中是每个房子的价格)。然后我们将每个数组数据转换为一个二维张量。
规范化数据
//Step 3. Normalize the data to the range 0 - 1 using min-max scalingconst inputMax = inputTensor.max();const inputMin = inputTensor.min(); const labelMax = labelTensor.max();const labelMin = labelTensor.min();const normalizedInputs = inputTensor.sub(inputMin).div(inputMax.sub(inputMin));const normalizedLabels = labelTensor.sub(labelMin).div(labelMax.sub(labelMin));
接下来,我们规范化数据。在这里,我们使用最小-最大比例将数据规范化为数值范围0-1。规范化很重要,因为您将使用tensorflow.js构建的许多机器学习模型的内部设计都是为了使用不太大的数字。规范化数据以包括0到1或-1到1的公共范围。
返回数据和规范化界限
return { inputs: normalizedInputs, labels: normalizedLabels, // Return the min/max bounds so we can use them later. inputMax, inputMin, labelMax, labelMin,} 我们可以在运行期间保留用于标准化的值,这样我们就可以取消标准化输出,使其恢复到原始规模,我们就可以用同样的方式规范化未来的输入数据。
步骤5:运行模型
通过创建模型实例、将数据表示为张量,我们可以准备开始运行模型。
将以下函数复制到script.js文件中。
async function trainModel(model, inputs, labels) { // Prepare the model for training. model.compile({ optimizer: tf.train.adam(), loss: tf.losses.meanSquaredError, metrics: ['mse'], }); const batchSize = 28; const epochs = 50; return await model.fit(inputs, labels, { batchSize, epochs, shuffle: true, callbacks: tfvis.show.fitCallbacks( { name: 'Training Performance' }, ['loss', 'mse'], { height: 200, callbacks: ['onEpochEnd'] } ) });} 我们把它分解一下。
准备运行
// Prepare the model for training. model.compile({ optimizer: tf.train.adam(), loss: tf.losses.meanSquaredError, metrics: ['mse'],}); 我们必须在训练前“编译”模型。要做到这一点,我们必须明确一些非常重要的事情:
:这是一个算法,它可以控制模型的更新,就像上面看到的例子一样。TensorFlow.js中有许多可用的优化器。这里我们选择了Adam优化器,因为它在实践中非常有效,不需要进行额外配置。
:这是一个函数,它用于检测模型所显示的每个批(数据子集)方面完成的情况如何。在这里,我们可以使用将模型所做的预测与真实值进行比较。
度量:这是我们要在每个区块结束时用来计算的度量数组。我们可以用它计算整个训练集的准确度,这样我们就可以检查自己的运行结果了。这里我们使用,它是的简写。这是我们用于损失函数的相同函数,也是回归任务中常用的函数。
const batchSize = 28;const epochs = 50;
接下来,我们选择一个批量大小和一些时间段:
batchSize指的是模型在每次运行迭代时将看到的数据子集的大小。常见的批量大小通常在32-512之间。对于所有问题来说,并没有一个真正理想的批量大小,描述各种批量大小的精确方式这一知识点本教程没有相关讲解,对这些有兴趣可以通过别的渠道进行了解学习。
epochs指的是模型将查看你提供的整个数据集的次数。在这里,我们通过数据集进行50次迭代。
启动列车环路
return model.fit(inputs, labels, { batchSize, epochs, callbacks: tfvis.show.fitCallbacks( { name: 'Training Performance' }, ['loss', 'mse'], { height: 200, callbacks: ['onEpochEnd'] } )}); model.fit是我们调用的启动循环的函数。它是一个异步函数,因此我们返回它给我们的特定值,以便调用者可以确定运行结束时间。
为了监控运行进度,我们将一些回调传递给model.fit。我们使用生成函数,这些函数可以为前面指定的“损失”和“毫秒”度量绘制图表。
把它们放在一起
现在我们必须调用从运行函数定义的函数。
将以下代码添加到运行函数的底部。
// Convert the data to a form we can use for training.const tensorData = convertToTensor(data);const {inputs, labels} = tensorData; // Train the model await trainModel(model, inputs, labels);console.log('Done Training'); 刷新页面时,几秒钟后,你应该会看到图形正在更新。
这些是由我们之前创建的回调创建的。它们在每个时代结束时显示丢失(在最近的批处理上)和毫秒(在整个数据集上)。
当训练一个模型时,我们希望看到损失减少。在这种情况下,因为我们的度量是一个误差度量,所以我们希望看到它也下降。
第6步:做出预测
既然我们的模型经过了训练,我们想做一些预测。让我们通过观察它预测的低到高数量房间的统一范围来评估模型。
将以下函数添加到script.js文件中
function testModel(model, inputData, normalizationData) { const {inputMax, inputMin, labelMin, labelMax} = normalizationData; // Generate predictions for a uniform range of numbers between 0 and 1; // We un-normalize the data by doing the inverse of the min-max scaling // that we did earlier. const [xs, preds] = tf.tidy(() => { const xs = tf.linspace(0, 1, 100); const preds = model.predict(xs.reshape([100, 1])); const unNormXs = xs .mul(inputMax.sub(inputMin)) .add(inputMin); const unNormPreds = preds .mul(labelMax.sub(labelMin)) .add(labelMin); // Un-normalize the data return [unNormXs.dataSync(), unNormPreds.dataSync()]; }); const predictedPoints = Array.from(xs).map((val, i) => { return {x: val, y: preds[i]} }); const originalPoints = inputData.map(d => ({ x: d.rooms, y: d.price, })); tfvis.render.scatterplot( {name: 'Model Predictions vs Original Data'}, {values: [originalPoints, predictedPoints], series: ['original', 'predicted']}, { xLabel: 'No. of rooms', yLabel: 'Price', height: 300 } );} 在上面的函数中需要注意的一些事情。
const xs = tf.linspace(0, 1, 100); const preds = model.predict(xs.reshape([100, 1]));
我们生成100个新的“示例”以提供给模型。model.predict是我们如何将这些示例输入到模型中的。注意,他们需要有一个类似的形状([num_的例子,num_的特点每个_的例子])当我们做培训时。
// Un-normalize the dataconst unNormXs = xs .mul(inputMax.sub(inputMin)) .add(inputMin); const unNormPreds = preds .mul(labelMax.sub(labelMin)) .add(labelMin);
为了将数据恢复到原始范围(而不是0–1),我们使用规范化时计算的值,但只需反转操作。
return [unNormXs.dataSync(), unNormPreds.dataSync()];
.datasync()是一种方法,我们可以使用它来获取存储在张量中的值的typedarray。这允许我们在常规的javascript中处理这些值。这是通常首选的.data()方法的同步版本。
最后,我们使用tfjs-vis来绘制原始数据和模型中的预测。
将以下代码添加到运行函数中。
testModel(model, data, tensorData);
刷新页面,现在已经完成啦!
现在你已经学会使用tensorflow.js创建一个简单的机器学习模型了。这里是Github存储库供参考。
结论
我开始接触这些是因为机器学习的概念非常吸引我,还有就是我想看看有没有方法可以让它在前端开发中实现,我很高兴发现tensorflow.js库可以帮助我实现我的目标。这只是前端开发中机器学习的开始,TensorFlow.js还可以完成很多工作。谢谢你的阅读!
本文由阿里云云栖社区组织翻译。
文章原标题《JavaScript for Machine Learning using TensorFlow.js》作者:Priyesh Patel 译者:么凹 审校:Viola
本文为云栖社区原创内容,未经允许不得转载。